
【説明書DL】.htaccessのリダイレクト – 書き方・設置場所・設定方法を解説します
2019年7月16日
東証スタンダード上場企業のジオコードが運営!
SEOがまるっと解るWebマガジン
更新日:2023年 01月 05日
 初心者向け解説!構造化データの仕組みと書き方を理解しよう
初心者向け解説!構造化データの仕組みと書き方を理解しよう
昨今検索結果には様々な情報が表示されます。
レシピ、有名人の写真、何かの作業手順など、検索結果のバリエーションは豊富です。
検索結果に影響を与える要素の一つ「構造化データマークアップ」について、この記事では解説します。
「ゴールはCV獲得!SEO、コンテンツマーケティング、UI・UX改善で、成果にコミット!」の株式会社ジオコードは、構造化データのほか、様々なアップデートを網羅的に対策します。
お気軽にご相談ください。
目次
構造化データとは「HTMLのデータに情報(意味)を付与するもの」です。
設定することで下記のようなメリットがあります。
●検索結果に構造化データに応じた内容が表示される(可能性がある)
●検索エンジンにマークアップした箇所の情報がより正確に伝わる
例えばこんな会話があったとします。
「Life is Beautiful、凄く良かったよ!」
この会話で言っている「Life is Beautiful」は一体何のことでしょう。
映画?音楽?本?名言?この内容だけだと、どれが正解かわからないですよね。
では、もしこの会話が下記のように変わったらどうでしょう。
「Life is Beautifulって映画、凄く良かったよ!」
誰が見ても「映画」のことだってわかりますよね。
「Life is Beautiful」に「映画」という情報(意味)を付与したことで情報が正確に伝わるようになりました。
こういった「意味付け」をWebページで(HTMLソースコード上で)行うのが構造化です。
検索エンジンはページの内容を正確に理解できれば、それだけ正しい評価を行うことができます。
構造化データを使うことで、正しい理解・評価に近づけることができるわけですね。
セマンティックWebとは、Webサイトが持つ意味をコンピュータに理解させ、コンピュータ同士で処理を行わせるための技術のことである。情報の意味(Semantics)をコンピュータ自身に理解させることで、人を仲立ちさせることなく情報のやりとりを行わせることができる。WWW関連技術の創始者であるティム・バーナーズ・リーによって提唱された。
引用: Weblio辞書
人間なら一目みてわかることであっても、検索エンジンが理解できるとは限りません。
例えば「リンゴ」を思い浮かべてみてください。
「赤い」「丸い」「食べ物」「フルーツ」のように色んなことをイメージできると思います。
ですが、検索エンジンはそうはいきません。
そこで「セマンティックWeb」という考えが登場します。
上記のように正確な情報を伝達できれば、人間に近い認識で処理できるようになります。
※構造化データは全ての情報をサポートしているわけではありません。
サポート項目については「schema.orgについて」の説明時にリンクを貼っています。
Googleの見解では、構造化データは検索順位に直接影響は与えません。
※下記動画でGoogleのJohn Mueller(ジョン・ミューラー)さんも説明していますね。
検索順位には影響がありませんが、「検索結果の表示」に影響を与えるメリットがあります。
条件次第ではリンクやURL、スニペットといった通常の検索結果とは異なる、設定した構造化データに応じた情報が表示されます。(リッチリザルトと呼びます)
有名なところでは「レシピ」の検索結果があります。
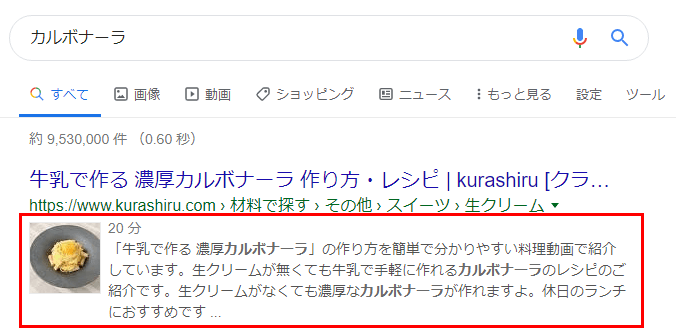
検索順位に直接の影響はなくても、間接的な影響は期待できます。
より多くの人の目にふれれば、ウェブ上で話題になったり、リンクを獲得する機会が増えます。
そういった「ウェブ上の人気」が集まれば、検索順位にプラスに働きます。
補足ですが、検索結果の表示に影響を与えるかは、設定する構造化データ次第になります。
検索結果に影響を与えないものもあります。
※下記ページにアクセスし、「構造化データ」をクリックすると種類を確認できます。
https://developers.google.com/search/reference/overview?hl=ja
構造化データを使えば、より「正確に・意図したとおり」ページの内容をGoogleに伝えられますが、
構造化データにもガイドラインがあるのです。
設定には注意が必要で、誤解を招くコンテンツや関連性のないコンテンツはガイドライン違反にあたります。
なお、SEOの基本的な概念は、【プロ直伝】最新のSEO徹底ガイド!対策手順と重要な考え方 を参考にしてください。
最初の方で「Life is Beautiful」という単語に「映画」という意味を付与した話をしました。
これは「Life is Beautiful」=「映画」と定義したとも言えます。
この定義するものが「ボキャブラリー」になります。
中でも「schema.org」が有名で、「何に」「何のボキャブラリー」を定義できるかが、まとめられています。
例えば「レシピ」の情報に「レシピ名」「カロリー」「作者」を割り当てることができる、といった感じですね。
あくまで「定義できるか」がわかるだけなので、ボキャブラリー単体では機能しません。
実際に構造化データを設定するためには記述方法であるシンタックスが必要です。
それぞれ詳しく説明します。
代表的なボキャブラリーは下記の二つです。
「Data-Vocabulary.org」は「schema.org」に役割を引き継いでいますので、実質「schema.org」一択になります。
他にも「GoodRelations」や「FOFA」などボキャブラリーには複数の種類が存在します。
ですが、前述したとおり使用するものは「schema.org」で大丈夫です。
後述する「MicroData」や「JSON-LD」と混同される方も見かけますが、それは「シンタックス」であり、そもそも別物になります。
シンタックスは、ボキャブラリーをHTMLに書く際の「記述のルール」です。
Googleがサポートしているシンタックスには下記の種類があります。
Googleの推奨は「JSON-LD」で、W3Cの推奨は「RDFa」です。
どのシンタックスでも機能しますが、上記推奨のどちらかを使用することをお勧めします。
※推奨しているシンタックスの方が今後のサポート改善を期待できますね。
各シンタックスについては、後ほど記述方法も含め説明します。
シンタックスの個別解説の前に、代表的なボキャブラリー「schema.org」について解説します。
schema.orgはGoogle・Yahoo!・Microsoftの大手検索エンジンが共同で作成しているボキャブラリーです。
構造化データとして認識させることを目的とし、日々膨大なデータの更新が行われています。
schema.orgはタイプ(type)とプロパティ(Property)を組み合わせて使用します。
映画「Life is Beautiful」を例に見てみると、下記のようになります。
※プロパティはたくさんの種類があります、以下はほんの一握りです。
●タイプ
Movie(映画)
●プロパティ
name(映画の名前)
actor(俳優)
director(監督)
なお、タイプの種類は「schema.org 日本語訳」で、プロパティは「https://schema.org/」で確認することができます。
プロパティを調べるときは、リンク先ページ右上の検索ボックスに「Movie」のようにプロパティ名を入れて検索すれば確認可能です。
前述した「JSON-LD」「Microdata」「RDFa」について、それぞれ解説します。
記述内容のボキャブラリーは全て「schema.org」を使用しています。
限定的な環境でのみマークアップが可能なシンタックスです。
HTMLソースコードの該当箇所の近くに、構造化データを記述します。
一か所で管理しないため更新が多少面倒ですが、変更漏れは少なくなります。(更新の際目に入るため)
HTML5でのみマークアップ可能で、W3Cの勧告は2013年10月で止まっています。
そのため、今後も使用を推奨できるシンタックスではありません。
※記述例
<div itemscope itemtype=”http://schema.org/Corporation”>
<span itemprop=”name”>株式会社ジオコード</span>
<span itemprop=”address” itemscope itemtype=”http://schema.org/PostalAddress”>
<span itemprop=”postalCode”>160-0022</span>
<span itemprop=”addressRegion”>東京都</span>
<span itemprop=”addressLocality”>新宿区</span>
<span itemprop=”streetAddress”>新宿4-1-6 JR新宿ミライナタワー10F</span></span>
<span itemprop=”telephone” content=”+81362748081″>03-6274-8081</span>
<span itemprop=”URL”>https://www.geo-code.co.jp/</span>
</div>
Microdataと近いマークアップ方法のシンタックスです。
HTMLソースコードの該当箇所の近くに、構造化データを記述します。
Microdata同様更新が多少面倒ですが、更新時の変更漏れは少なくなります。
また、「HTML5のみ」のような環境制限がなく、広い言語でマークアップ可能です。
なお、正確には「RDFa Lite」になります。
※記述例
<div vocab=”http://schema.org/” typeof=”Corporation”>
<span property=”name”>株式会社ジオコード</span>
<span property=”address” typeof=”PostalAddress”>
<span property=”postalCode”>160-0022</span>
<span property=”addressRegion”>東京都</span>
<span property=”addressLocality”>新宿区</span>
<span property=”streetAddress”>新宿4-1-6 JR新宿ミライナタワー 10F</span></span>
<span property=”telephone” content=”+81362748081″>03-6274-8081</span>
<span property=”URL”>https://www.geo-code.co.jp/</span>
</div>
microdataやRDFaとは記述場所が異なり、JSON-LDは設定箇所とは別に記述します。
記述場所はHTML内のどこでもOKで、管理面は楽そうですね。
ただし、元のHTMLのソースコードと構造化データの記述箇所が異なりますので、更新漏れだけ注意が必要です。
※記述例
<script type=”application/ld+json”>
{
“@context”: “http://schema.org”,
“@type”: “Corporation”,
“name”: “株式会社ジオコード”,
“address”: {
“@type”: “PostalAddress”,
“postalCode”: “160-0022”,
“addressRegion”: “東京都”,
“addressLocality”: “新宿区”,
“streetAddress”: “新宿4-1-6 JR新宿ミライナタワー 10F”
},
“telephone”: “+81362748081”,
“URL”: “https://www.geo-code.co.jp/”
}
</script>
この例を見てもわかるように、既存の記述があれば固有の情報を変更することで、設定できます。
※もちろん不足がある場合は追加が必要ですけどね。
電話番号については国番号の指定が必要で「+81」が該当します。(日本を指します)
補足ですが、左側の”name”などを「key(属性)」と呼び、右側の”株式会社ジオコード”などを「value(値)」と呼びます。
「key」と「value」を1セットとして、定義を進めていくわけですね。
構造化データは種類が多く、記述が正しいかは都度確認が必要になります。
次のセクションで、構造化データの確認や参考や確認に便利な「構造化データテストツール」を紹介します。
構造化データを設定しても記述が誤っていたら、正しく処理されません。
設定した構造化データは「構造化データテストツール」で問題ないか確認することができます。
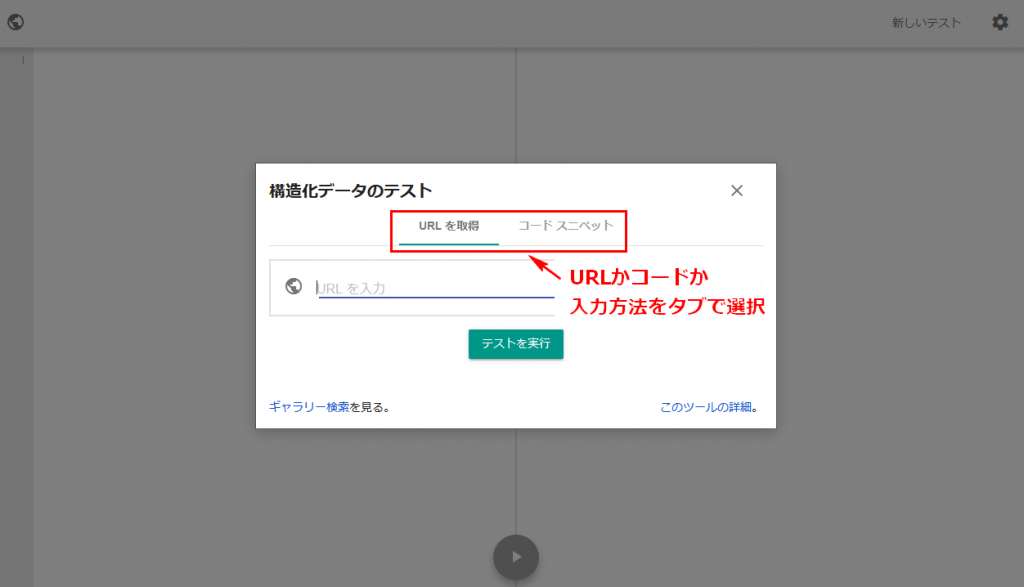
対象のURL、もしくはソースコードを入力するとテスト結果が表示されます。
※「URLを取得」「コードスニペット」のタブを選択できます。
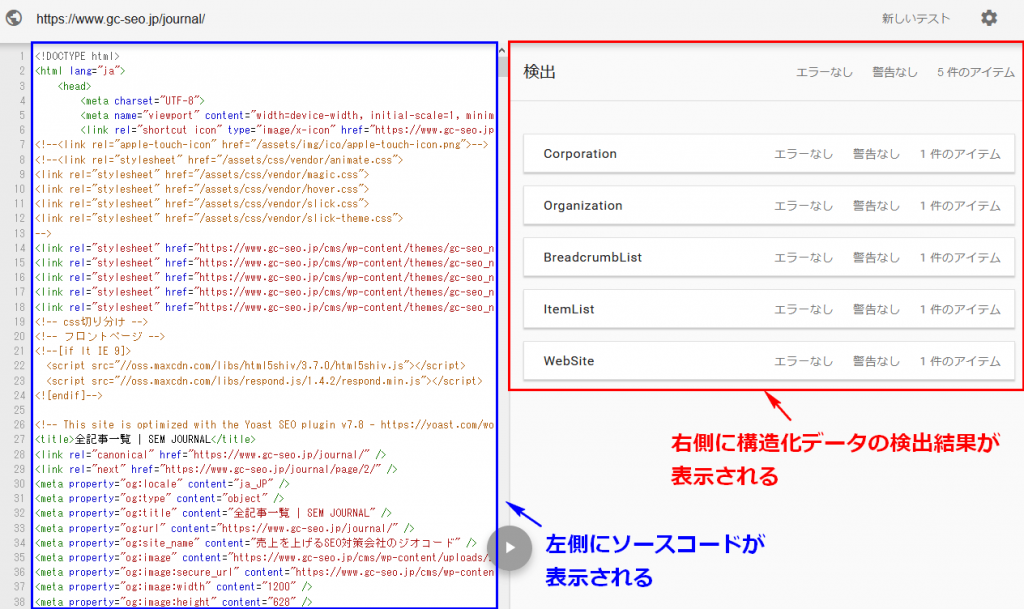
テスト結果の左にはソースコードが、右側には検出結果が表示されます。
検出された構造化データの内容や、エラーや警告の有無を確認することができます。
画像ではエラーがないので「エラーなし」の表示ですね。
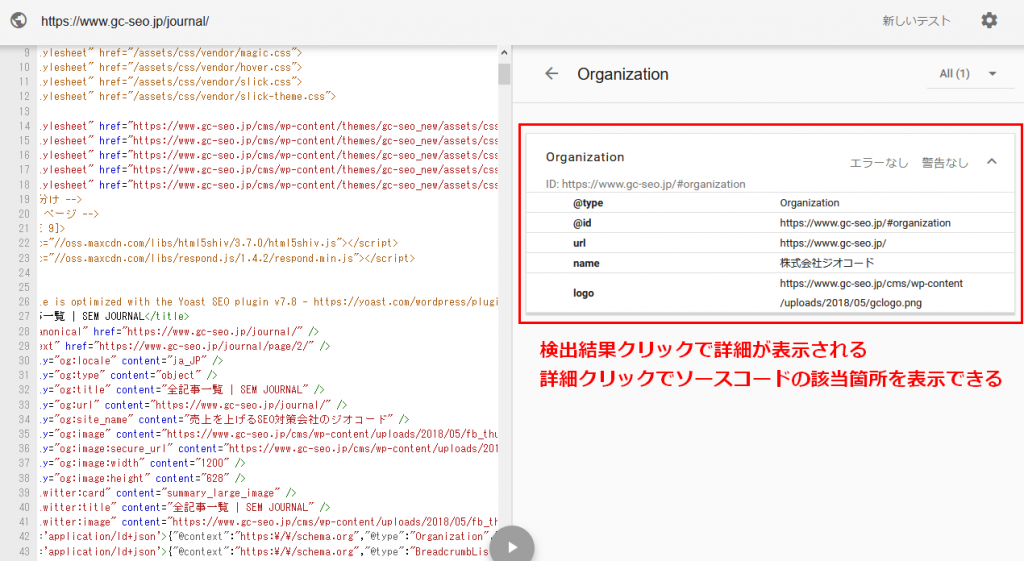
右側の検出結果はクリックすると詳細を見ることができます。
また、詳細をさらにクリックすると、該当箇所のソースコードを表示してくれます。
該当箇所が一目でわかるので、とても便利な機能です。
こちらのツールはURLや記述がわかれば使用可能です。
すでに設定されているサイトをツールにかければ、記述を参考にすることもできますね。
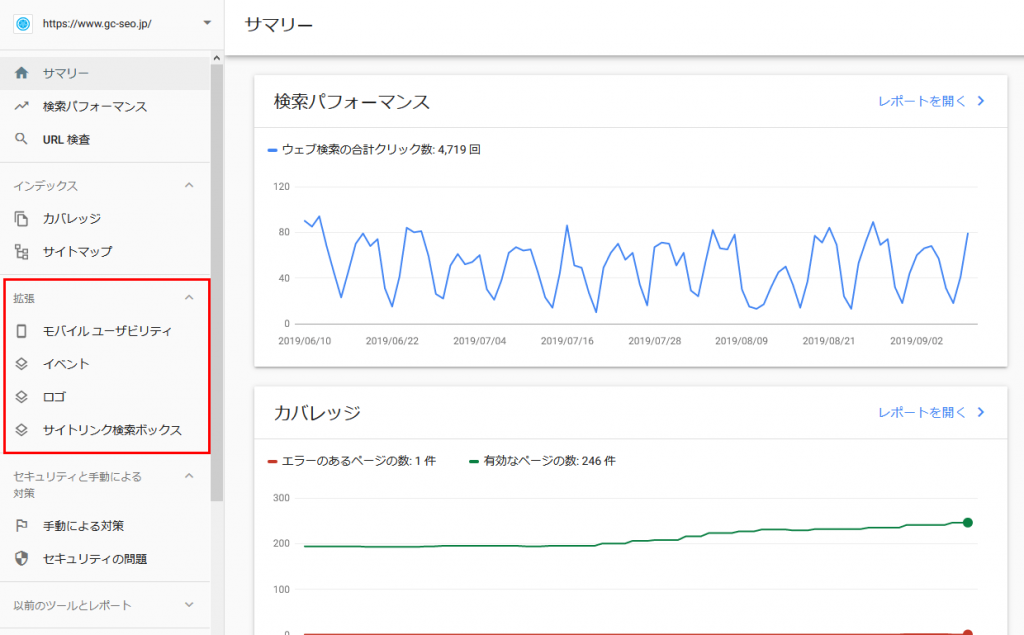
構造化データにエラーがあると「拡張」カテゴリーに表示されます。
※画像は弊社ドメインのもので、現状エラーがないため表示もありませんね…
旧バージョンのSearchconsoleでは「検索のデザイン」>「構造化データ」から確認できましたが、現在は確認箇所が変わり、上記に変更になっています。
※旧SearchConsoleは2019年の9月に、一部ツールを残してサービスの提供を終了しています。
「検索結果」の表示はここ数年で見違えるほど変わりました。
検索結果で目的を達成し、どのサイトにもアクセスしない「0クリック」も増えているほどです。
今後はただ検索順位を上げるだけでなく、他のアプローチ方法も認識しておく必要があります。
逆に言えば、順位以外での打ち手が与えられたとも言えます。
構造化データのサポート範囲は増えていますので、常に最新情報にアンテナを張っておくといいですね!
「対応方法が分からない」「自分でやっても上手くいかない」とお悩みの方には
実装も可能なジオコードのSEOがおすすめです!
「ゴールはCV獲得!SEO、コンテンツマーケティング、UI・UX改善で、成果にコミット!」の株式会社ジオコードは、構造化データのほか、様々なアップデートを網羅的に対策します。
お気軽にご相談ください。

ゴールはCV獲得!SEO、コンテンツマーケティング、UI・UX改善で、成果にコミット!
東証スタンダード上場企業が支援。18年間のノウハウを全て提供!SEO内製化を支援する唯一無二のサービス
リスティング、SNS、動画広告まで、ありとあらゆる業種で成果にコミット!
マーケティング会社だから出来るWeb制作!「SEO」「UI 設計」「記事コンテンツ」が標準搭載!
見込み顧客の獲得、育成から、商談管理、顧客管理まで、MA、SFA、CRMの全てを搭載!
自動集計で間違いなし!申請、確認の手間を大幅削減!クラウド勤怠管理、交通費精算、経費精算ツール、ネクストICカード
Webマーケティング&営業DXで、集客から、受注までの全てを一社完結
「社会の模範となる、唯一無二の魅力的な会社を創る仲間」を募集しています
ネクストSFAのジオコードによる、営業組織を強くするWebマガジン
基礎から最新のトレンド情報まで、SEOのことがまるっと解るWebマガジン
RLSA?CPA?用語が多すぎるWeb広告、基礎から学べるWebマガジン
Web制作の現場で良く使われる用語や技術について、基本が解るWebマガジン














